

如果您也和我一样准备春招,只为
TOP20大厂,欢迎加我微信shunwuyu,一起交流面经,一起屡败屡战。
前言
如果您想在localhost部署并运行开源大模型,可以试试Ollama。本文我们将使用Ollama部署,并通过API的方式调用大模型。
安装
Ollama提供了python和js两种开发包,对前端开发者挺友好的,用它!
复制代码pip install ollama npm install ollama
应用场景
-
聊天接口
-
多模态
模型
我们可以通过 library (ollama.com) 查看Ollama支持的模型清单,有gemma、llama2、mistral、mixtral等,非常的丰富。
比如我们要使用的开源模型是llama2, 我们可以使用如下代码下载(首次)并运行模型
bash复制代码# 拉取模型 ollama pull llama2 # 运行模型 ollama run llama2
接口
如果我们使用过openai的一些接口, 那么就了解文本补全、聊天、嵌入等。ollama提供了REST API来提供了请求接口。
- 生成式接口
python复制代码curl http://localhost:11434/api/generate -d ''{ "model": "llama2", "prompt":"Why is the sky blue?" }''
- 聊天接口
python复制代码curl http://localhost:11434/api/chat -d ''{ "model": "mistral", "messages": [ { "role": "user", "content": "why is the sky blue?" } ] }''
- 嵌入
python复制代码curl http://localhost:11434/api/embeddings -d ''{ "model": "all-minilm", "prompt": "Here is an article about llamas..." }''
实战
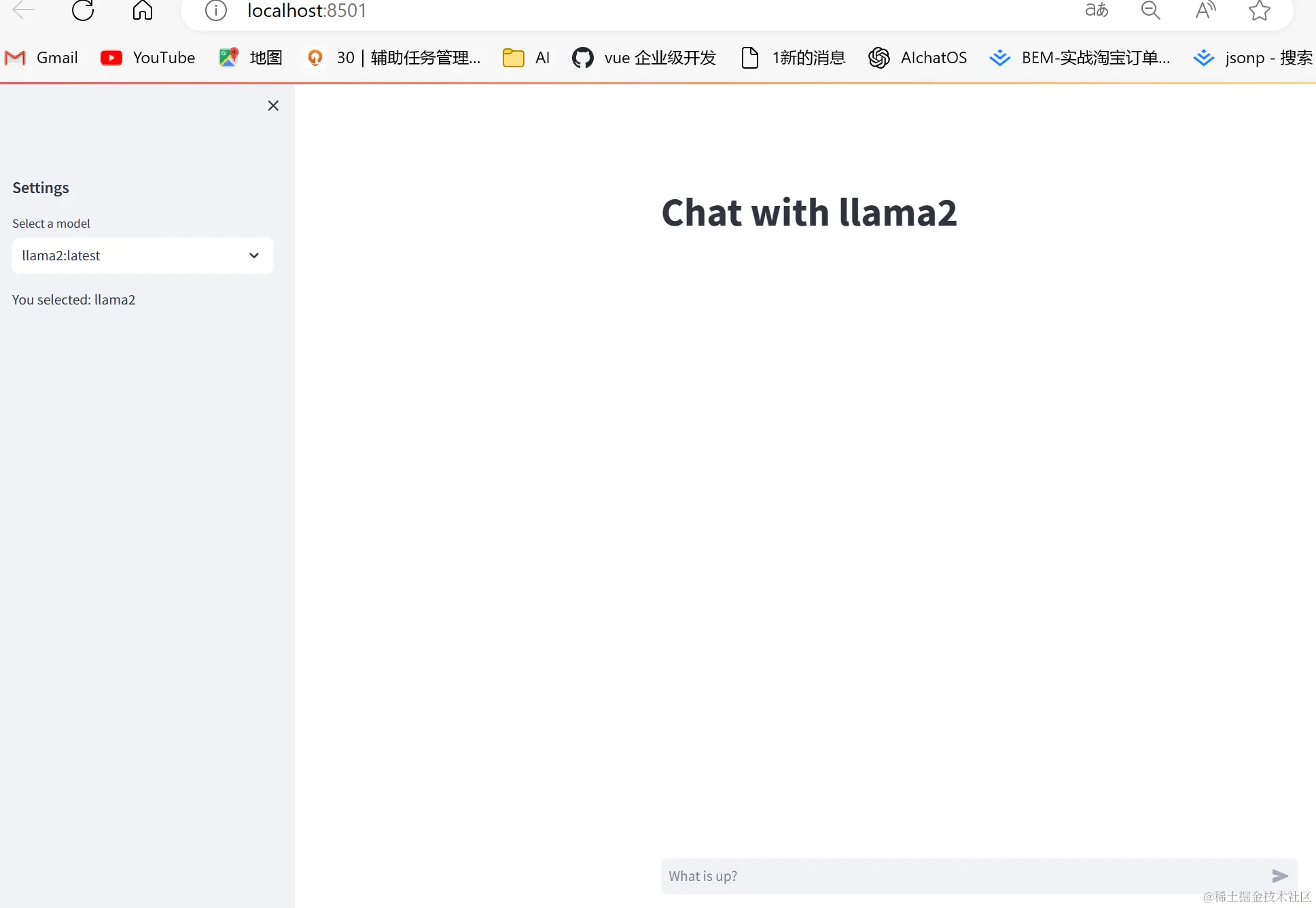
我们将结合Streamlit和Ollama,开发一个聊天应用。
Streamlit是一款Web开发框架,适用于python快速完成一些大模型、数学科学计算的UI开发。
我们还会用到 Build a ChatGPT-like App | Streamlit 代码快速构建类chatgpt应用。
python复制代码# 引入streamlit UI库 import streamlit as st # 引入 ollama import ollama # 获取ollama的模型列表 model_list = ollama.list() # 设置默认模型名字为 llama2:7b-chat if "model_name" not in st.session_state: st.session_state["model_name"] = "llama2:7b-chat" # 初始化聊天信息数组 if "messages" not in st.session_state: st.session_state.messages = [] # 设置边栏 with st.sidebar: # 侧边栏的标题 st.subheader("Settings") # 下拉框 选择模型, 默认选中llama2 option = st.selectbox( ''Select a model'', [model[''name''] for model in model_list[''models'']]) st.write(''You selected:'', option) st.session_state["model_name"] = option # 页面标题 与llama聊天 st.title(f"Chat with {st.session_state[''model_name'']}") # 遍历聊天数组 for message in st.session_state.messages: # 根据角色 with st.chat_message(message["role"]): # 输出内容 st.markdown(message["content"]) if prompt := st.chat_input("What is up?"): st.session_state.messages.append({"role": "user", "content": prompt}) with st.chat_message("user"): st.markdown(prompt) with st.chat_message("assistant"): # 大模型返回后就清空输入框 message_placeholder = st.empty() full_response = "" for chunk in ollama.chat( model=st.session_state["model_name"], messages=[ {"role": m["role"], "content": m["content"]} for m in st.session_state.messages ], # 逐渐打出 stream=True, ): if ''message'' in chunk and ''content'' in chunk[''message'']: full_response += (chunk[''message''][''content''] or "") message_placeholder.markdown(full_response + "▌") message_placeholder.markdown(full_response) st.session_state.messages.append({"role": "assistant", "content": full_response})
- 拉取模型
ollama pull

除了llama2, 我们再拉取下orca-mini
- 列出当前所有模型
ollama list

- 运行streamlit
streamlit run app.py
总结
Ollama在本地部署开源大模型,真心方便且靠谱。 我在红米老爷机上运行了, 可以。- 结合streamlit 快速将Web搭建了出来。




