
1 大模型知识更新的困境
- 大模型的知识更新是很困难的,主要原因在于:
- 训练数据集固定,一旦训练完成就很难再通过继续训练来更新其知识
- 参数量巨大,随时进行fine-tuning需要消耗大量的资源,并且需要相当长的时间
- LLM的知识是编码在数百亿个参数中的,无法直接查询或编辑其中的知识图谱
- ——>LLM的知识具有静态、封闭和有限的特点。
- ——>为了赋予LLM持续学习和获取新知识的能力,RAG应运而生
2 RAG介绍
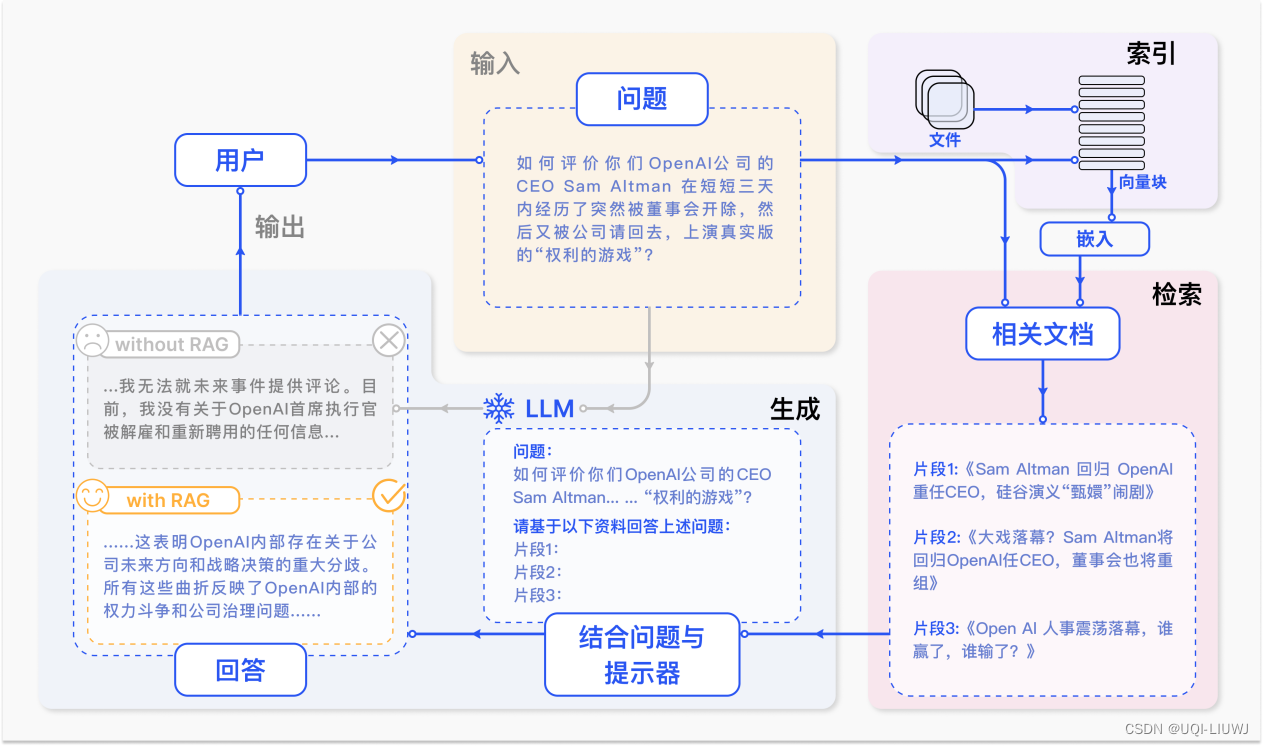
这是一个RAG的例子,来自专补大模型短板的RAG有哪些新进展?这篇综述讲明白了
- 我们向 ChatGPT 询问 OpenAI CEO Sam Atlman 在短短几天内突然解雇随后又被复职的事情。
- 由于受到预训练数据的限制,缺乏对最近事件的知识,ChatGPT 则表示无法回答。(without RAG)
- RAG 则通过从外部知识库检索最新的文档摘录来解决这一差距。
- 它获取了一系列与询问相关的新闻文章。
- 这些文章,连同最初的问题,随后被合并成一个丰富的提示,使 ChatGPT 能够综合出一个有根据的回应
- 将大规模语言模型(LLM)与来自外部知识源的检索相结合,以改进大模型的问答能力
- 核心手段是利用外挂于LLM的知识数据库(通常使用向量数据库)存储未在训练数据集中出现的新数据、领域数据等
2.1 RAG 三阶段
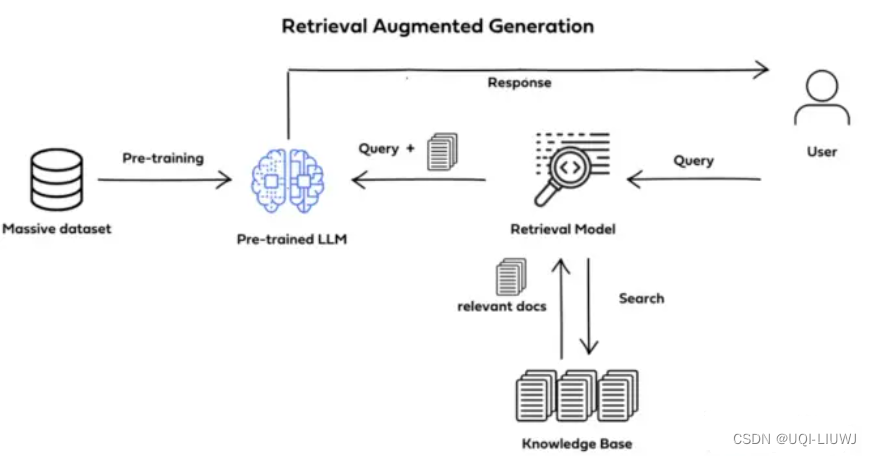
- RAG将知识问答分成三个阶段:
- 索引
- 事先将文本数据进行处理,通过词嵌入等向量化技术,将文本映射到低维向量空间,并将向量存储到数据库中,构建起可检索的向量索引
- 知识检索
- 当输入一个问题时,RAG会对知识库进行检索,找到与问题最相关的一批文档
- 生成答案
- RAG会把输入问题及相应的检索结果文档一起提供给LLM,让LLM充分把这些外部知识融入上下文,并生成相应的答案。
- RAG控制生成长度,避免生成无关内容
-
- def question_answering(context, query):
- prompt = f"""
- Give the answer to the user query delimited by triple
- backticks ```{query}```\
- using the information given in context delimited by triple
- backticks ```{context}```.\
- If there is no relevant information in the provided context,
- try to answer yourself,
- but tell user that you did not have any relevant context
- to base your answer on.
- Be concise and output the answer of size less than 80
- tokens.
- """
- response = get_completion(instruction, prompt, model="gpt-3.5-turbo")
- answer = response.choices[0].message["content"]
- return answer
这里的context就是RAG找到的=
- 索引
3 RAG特点
3.1 优点
- 可以利用大规模外部知识改进LLM的推理能力和事实性
- 第一阶段的知识索引可以随时新增数据,延迟非常低,可以忽略不计。
- 因此RAG架构理论上能做到知识的实时更新,不需要重新设置/train大模型
- 可解释性强,RAG可以通过提示工程等技术,使得LLM生成的答案具有更强的可解释性,从而提高了用户对于答案的信任度和满意度
-
RAG弥补了大模型处理token长度的限制,对于非常大的知识库,也可以进行检索生成。
-
上下文知识并不是越多越好,而是要精确,由于大模型的注意力机制,过多的内容也可能会导致大模型被带偏,不能给出准确的答案。
-
-
RAG 模型可以通过限制知识库的权限来实现安全控制,确保敏感信息不被泄露,提高了数据安全性。
-
.高度定制能力:RAG 模型可以根据特定领域的知识库和 prompt 进行定制,使其快速具备该领域的能力。说明 RAG 模型广泛适用于的领域和应用,
3.2 缺点
- 知识检索阶段(第二阶段)依赖相似度检索技术,并不是精确检索,因此有可能出现检索到的文档与问题不太相关
- 在第三阶段生产答案时,由于LLM基于检索出来的知识进行总结,从而导致无法应对用户询问知识库之外的问题
- 外部知识库的更新和同步,需要投入大量的人力、物力和时间
- 需要额外的检索组件,增加了架构的复杂度和维护成本
-
内容会受到检索结果局限。有些创造性的任务,本身是想通过大模型获取新的灵感,然而检索结果给到大模型后,大模型往往容易受到限制,这个限制在有些时候是好事,但并非所有时候。
4 RAG可以解决的问题
- 模型幻觉问题
- LLM文本生成的底层原理是基于概率进行生成的,在没有已知事实作为支撑的情况下,不可避免的会出现一本正经的胡说八道的情况
- 时效性问题
- 具有一定时效性的数据就可能无法及时参与 训练,造成模型无法直接回答与时效性相关的问题
- 数据安全问题
- 开源的LLM是没有企业内部数据和用户数据的,如果企业想在保证数据安全的前提下使用LLM,一种比较好的解决办法就是把数据放在本地
- 企业数据的业务计算全部放在本地完成,在线的LLM只是完成一个归纳总结的作用
5 RAG几个关键部分
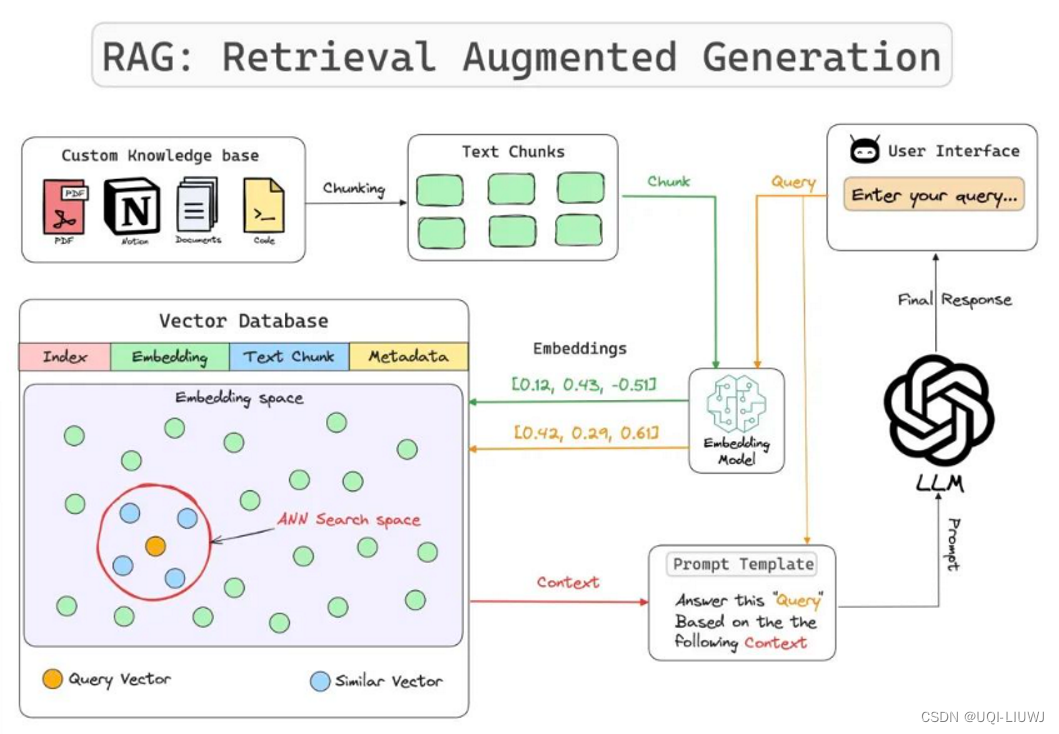
5.1 定制知识库
定制知识库是指一系列紧密关联且始终保持更新的信息集合,它构成了 RAG 的核心基础
5.2 分块
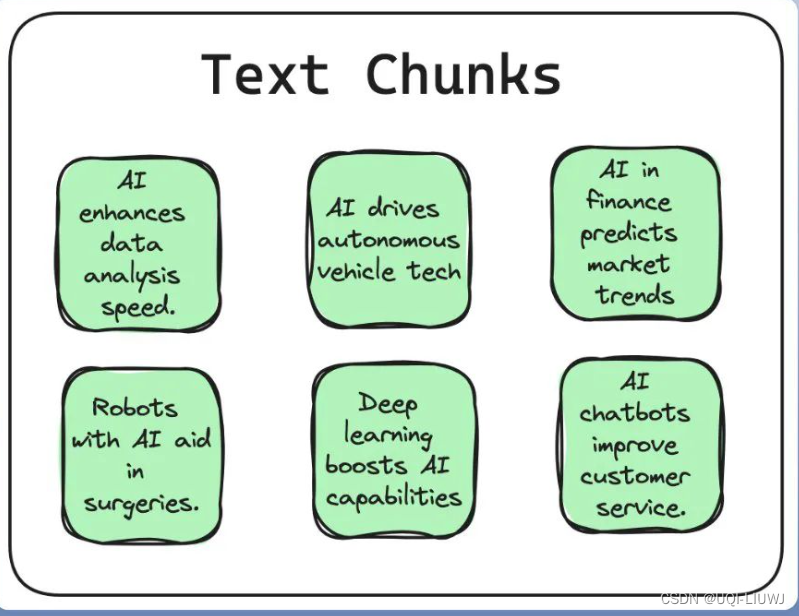
- 分块技术是指将大规模的输入文本有策略地拆解为若干个较小、更易管理的片段的过程。
- 这一过程旨在确保所有文本内容均能适应嵌入模型所限定的输入尺寸,同时也有助于显著提升检索效率。
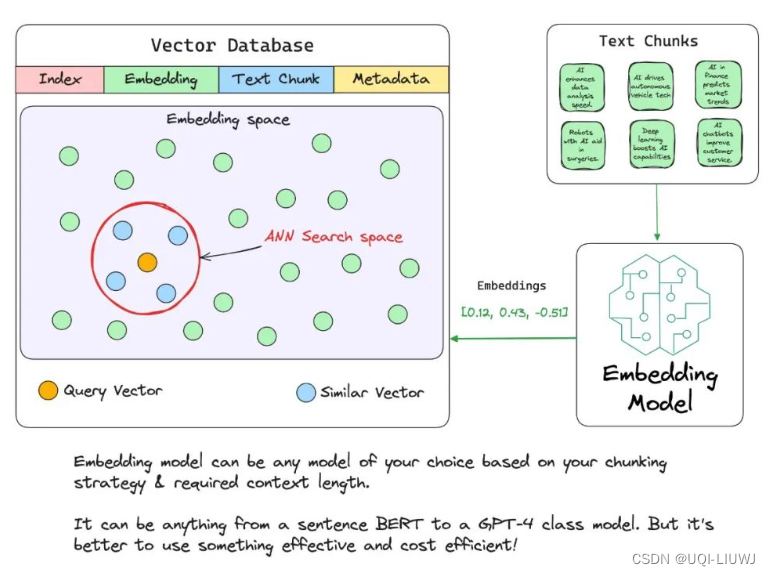
5.3 Embedding 嵌入 & Embedding Model 嵌入模型
- 将文本数据表示为数值向量
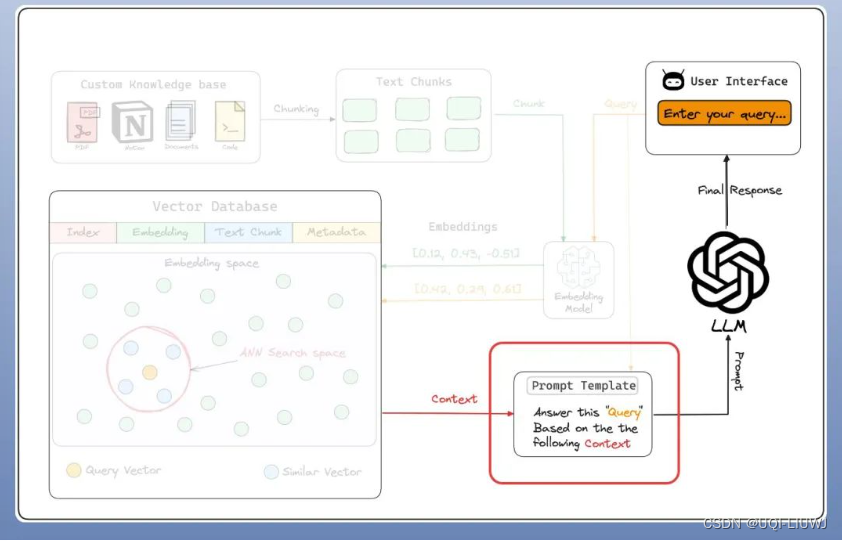
5.4 提示模板
为 RAG 系统生成合适提示的过程,可以是用户查询和定制知识库的组合。
这作为输入给 LLM,产生最终回复。
参考内容:RAG从入门到精通-RAG简介 – Ace Consider




